// PRIVATER LLM-CLUSTER · SELF-HOSTED
Bring Your
Own GPU.
Nutze deine vorhandene Hardware als privaten KI-Cluster. Ohne Cloud-Anbindung, ohne laufende Token-Kosten und mit voller Kontrolle darüber, wo deine Daten bleiben.
// und Apple-Silicon-Clients können die Performance weiter steigern.
Warum lokale KI-Inference?
Cloud-KI kostet — und wirft Datenschutzfragen auf
Je nach Modell und Aufgabe kosten Cloud-APIs zwischen 0,55 € und 14 € pro Million Output-Token. Bei regelmäßigem Einsatz summiert sich das. Und wohin die Daten dabei gehen, bleibt oft unklar. KNUT läuft im eigenen Netzwerk: ohne Token-Kosten, ohne externe Datenweitergabe.
Vorhandene Hardware als ungenutztes Potenzial
Viele Unternehmen haben bereits leistungsfähige Hardware im Haus: Gaming-GPUs, Workstations, ausgemusterte Server. Statt diese Ressourcen brachliegen zu lassen, lassen sie sich mit KNUT zu einem gemeinsamen KI-Cluster zusammenschalten. Die vorhandene Investition fängt an zu arbeiten.
Einzelne Rechner stoßen schnell an ihre Grenzen
Die meisten lokalen KI-Lösungen laufen auf einem einzelnen Rechner oder einer einzelnen GPU. Wer mehr Leistung oder Ausfallsicherheit braucht, findet kaum pragmatische Alternativen. KNUT verteilt die Last auf mehrere Nodes und wächst mit, wenn weitere Hardware dazukommt.
Der Mittelstand braucht pragmatische Lösungen
Was viele Unternehmen wirklich brauchen, ist keine komplexe Cloud-Infrastruktur, sondern eine Lösung, die mit vorhandener Hardware funktioniert. Ohne monatelange Einrichtung, ohne spezialisiertes DevOps-Team. KNUT ist darauf ausgelegt, schnell produktiv zu sein.
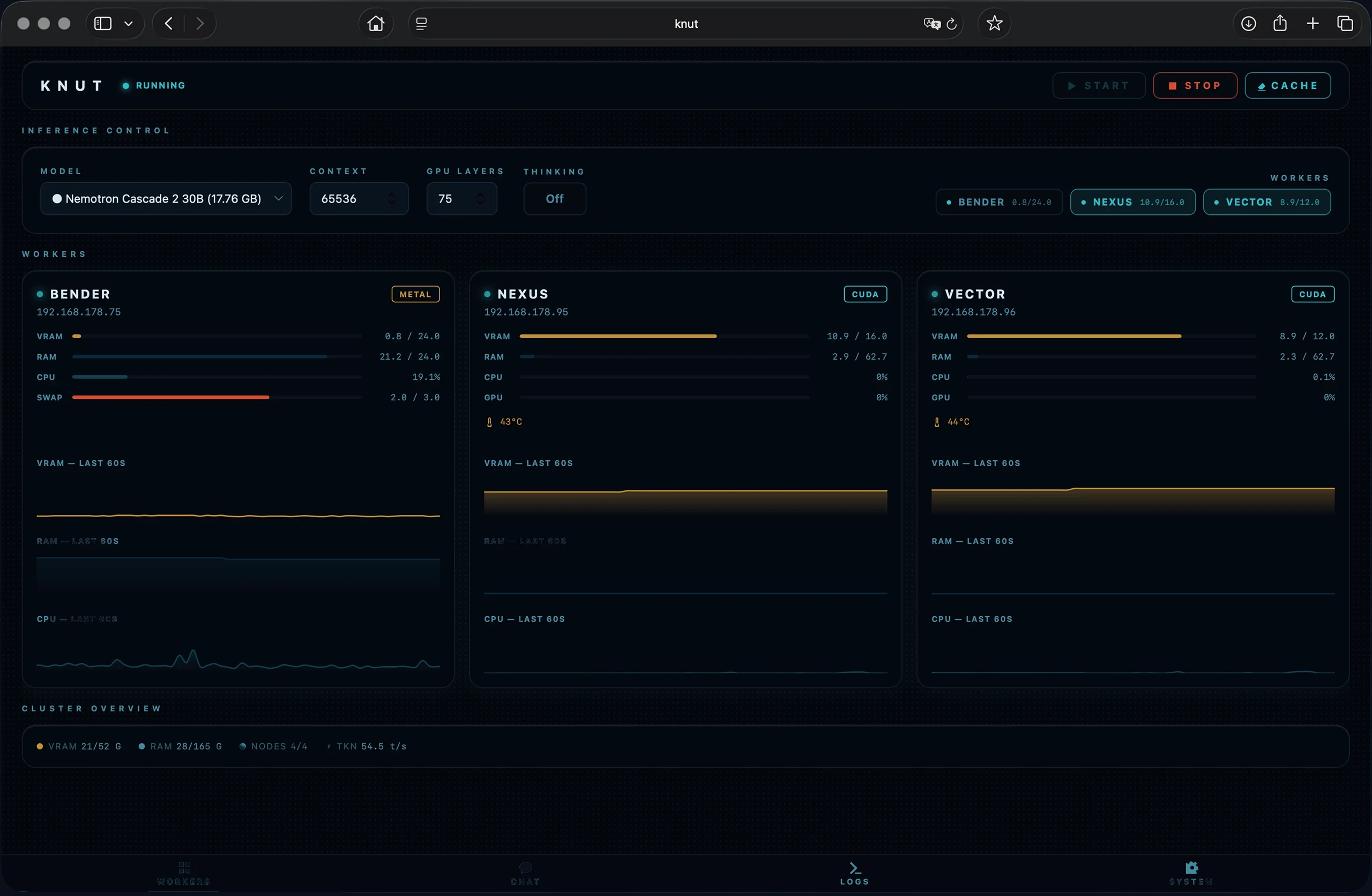
Was kann KNUT?
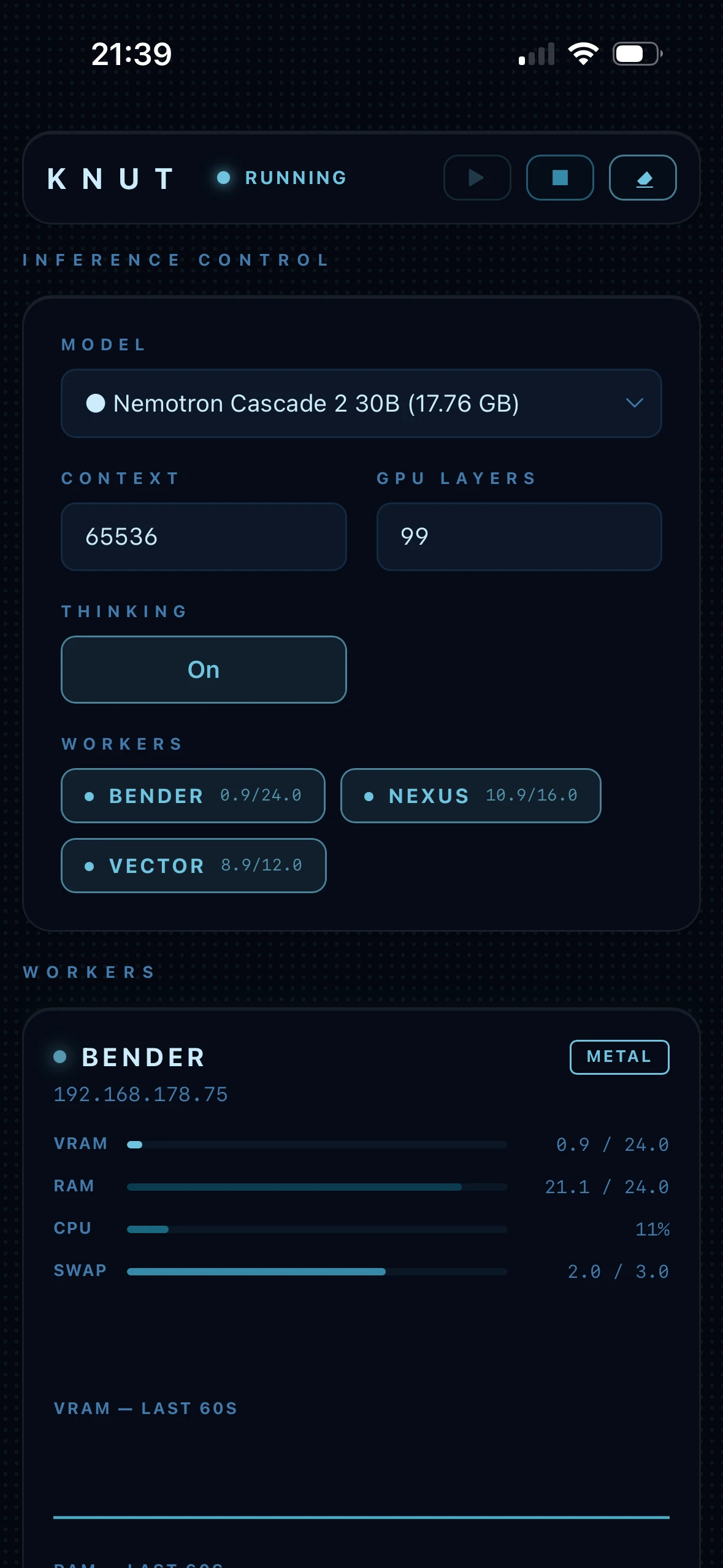
KNUT verbindet mehrere Rechner zu einem gemeinsamen KI-Cluster, der sich im eigenen Netzwerk betreiben lässt. Mit OpenAI-kompatibler API, Echtzeit-Dashboard und automatischer Crash-Recovery. Das Beispiel-Cluster zeigt: Bereits mit zwei CUDA-Nodes lassen sich lokal ohne Cloud auf aktuellen 30B-Modellen wie Nemotron Cascade 2 über 50 t/s erreichen. Weitere Nodes oder Apple-Silicon-Clients können den Durchsatz weiter erhöhen.
MULTI-GPU / MULTI-NODE
NVIDIA- und Apple-Silicon-Nodes lassen sich kombinieren. Das Beispiel-Setup erreicht bereits über 50 t/s. Jeder weitere Node oder Apple-Silicon-Client kann die Performance weiter steigern.
LOKAL · DATENSOUVERÄN
Ohne Rate Limits, ohne externe Datenzugriffe. Du entscheidest, welche Modelle laufen und wie sie konfiguriert sind. Die Daten verlassen das eigene Netzwerk nicht.
OPENAI-KOMPATIBEL
KNUT verhält sich wie die OpenAI-API. Bestehende Integrationen lassen sich in der Regel ohne Code-Änderungen übernehmen.
Für wen ist KNUT gedacht?
n8n · LangChain · Workflows
Du baust n8n- oder LangChain-Workflows und möchtest Token-Kosten reduzieren, oder einfach ohne API-Limits arbeiten können.
2+ NVIDIA-GPUs oder Apple Silicon
Du hast NVIDIA-GPUs oder Apple-Silicon-Geräte im Einsatz und möchtest mehr daraus machen, als sie brachliegen zu lassen.
Compliance · DSGVO · Kontrolle
Dein Unternehmen möchte KI-Unterstützung nutzen, aber Compliance-Anforderungen oder Datenschutzrichtlinien machen Cloud-Dienste schwierig.
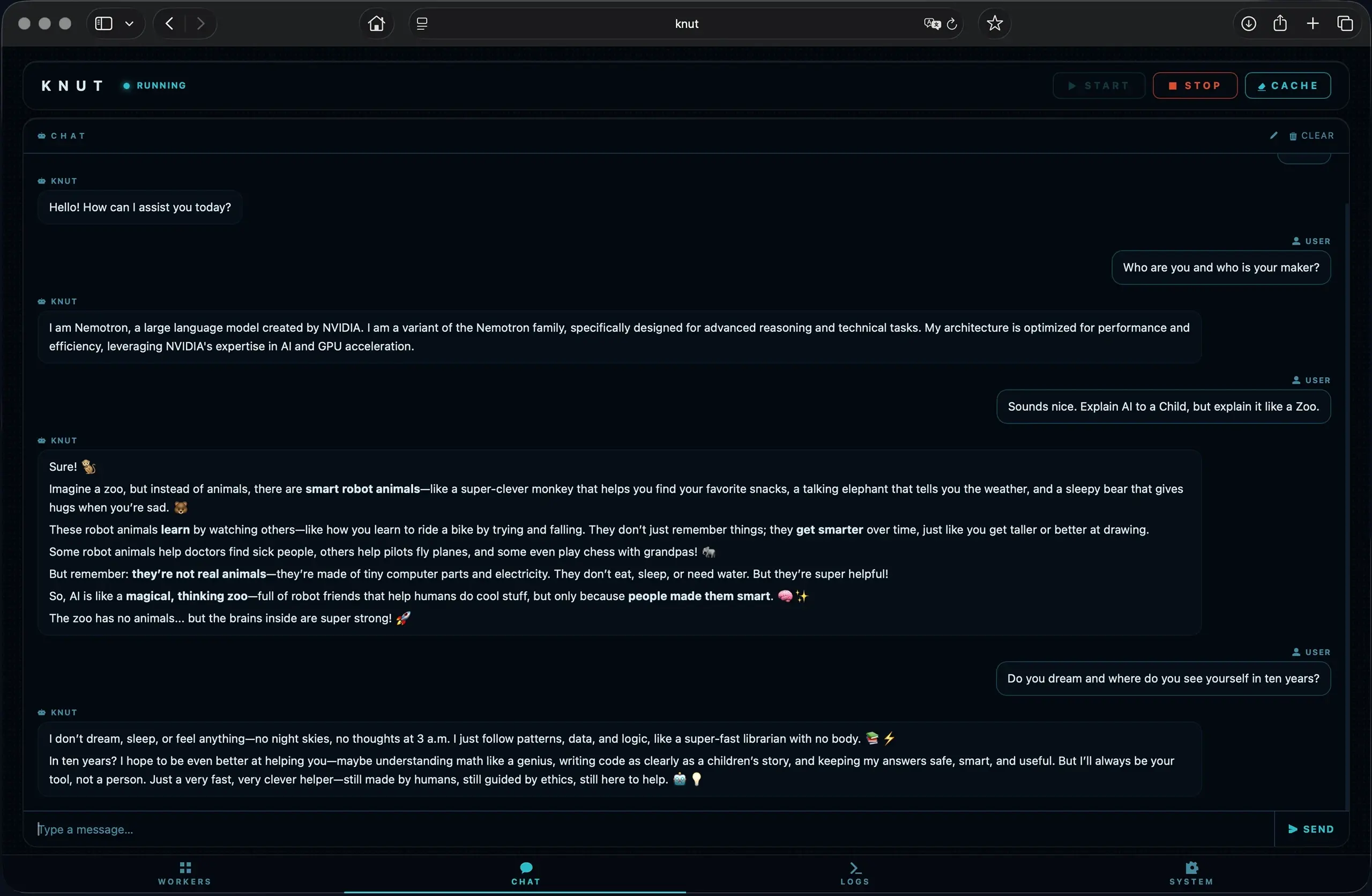
Überall verfügbar: vom Smartphone bis zum Desktop.
Das KNUT-Dashboard passt sich an jede Bildschirmgröße an, ob du den Cluster-Status kurz auf dem Smartphone prüfst oder das vollständige System-Monitoring am Desktop nutzt.
Eine separate App wird nicht benötigt. Das Web-UI läuft direkt im Browser, lokal im LAN erreichbar. Kein App-Store, keine externen Abhängigkeiten.
Technische Grundlage
// Gemessene Werte aus dem laufenden Beispiel-Cluster. Mehr Nodes und Apple-Silicon-Clients können Durchsatz und verfügbaren VRAM weiter erhöhen.
Dabei sein, wenn KNUT startet.
Du bekommst frühen Zugang zur Beta, Hilfe beim Einrichten und Updates nur dann, wenn es wirklich etwas Neues gibt.
Kein Rauschen, kein Spam.